.png?width=365&height=122&name=BTLogo%20(1).png)

.jpeg)
Every engineer wants to ship high-quality software systems, but the “how” isn’t always straightforward. To help, we designed a testing series, “Shipping code quickly with confidence.” Using code from sendsecure.ly, a Basis Theory lab project, readers will bring together the testing layers and strategies used by our data tokenization platform to achieve its 0% critical and major defect rate. You can find the links to all published articles at the bottom of each blog.
Our results
As of publication, a team of 8 engineers at Basis Theory have had 3,353 pull requests merged in the last 12 months—with zero production issues reported by customers.
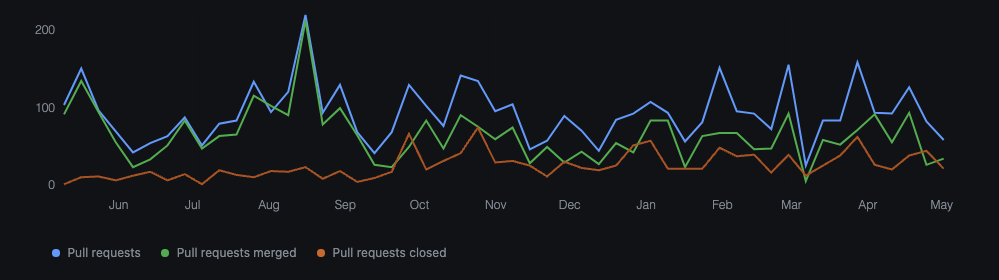
There’s always room for improvement, but our current approach allows any engineer to confidently contribute to any part of our system without the fear of impacting customers or compromising our security and compliance postures.
We felt a foundation was needed before getting to the real-world examples and working code samples in the blogs to follow, so this article will do just that by outlining some of the different test methods and principles used by Basis Theory across our teams.
Testing Layers: A Swiss Cheese Testing model
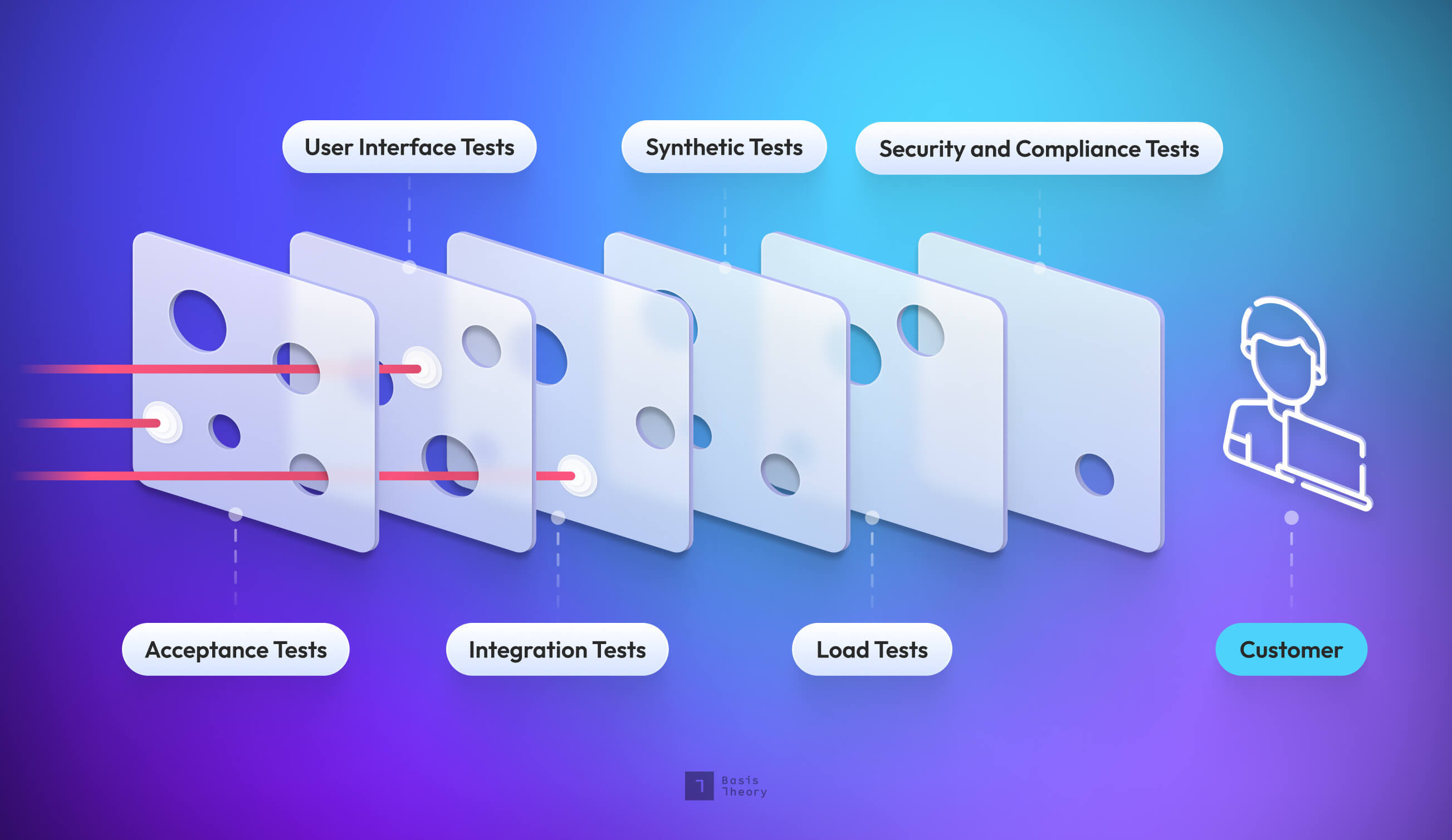
As a compliant and developer-friendly platform for securing and using sensitive data, our customers rely on a healthy system that performs as intended. At Basis Theory, we use a multi-layered testing approach that catches bugs, reduces feedback loops to developers, and increases confidence across the board.
Here’s a snapshot of the tests we use today.
- Unit Tests - A unit test tests a small piece of code in isolation, typically a function or property. These tests mock or stub all dependencies to ensure isolation from the rest of the system. They are the cheapest to write and the fastest to run.
- Acceptance Tests - These tests ensure a system's behavior satisfies all business requirements, aka acceptance criteria. An example may be testing the security of an API, or that a program correctly writes data to a database. Acceptance tests treat the system under test (SUT) as a black box—only interacting with the SUT through its public interface. These tests utilize mocks and stubs of external dependencies such as an API or database. Unlike unit tests, these tests are typically slower because they require running the entire application in isolation.
- UI Tests - UI tests ensure the visual elements of an application work as intended, checking the graphical user interface (GUI) for any behavior, accessibility, or rendering issues, such as ensuring the UI displays correctly various devices and screen sizes. These tests can also be used to serve as integration tests and typically employ UI-automation frameworks, for instance, Selenium or Cypress, to drive UI interaction.
- Integration Tests - Integration tests ensure communication and configurations work as intended when deployed with live dependencies, such as a development or staging environment. Over time, integration tests may introduce potential flakiness due to statefulness in the application and the availability of dependencies.
- Synthetic Tests - Synthetic tests check behavior across multiple software systems from an end user's perspective, simulate real traffic, and can be performed from as many geographic locations as needed. These tests typically check for a happy path of core business functions within a system. An example may be a user signing up, logging in, searching for a product, adding a product to a shopping cart, and performing a checkout.
- Load Tests - Load tests simulate user and system interactions with a software system and can be used to monitor for performance degradation introduced by changes in dependencies or new functionality.
- Security/Compliance Tests - Whether internally set or externally required (e.g., PCI), many organizations have security and compliance requirements to consider. Utilizing tests that perform code, container, network, and system scanning identify vulnerabilities and potential security risks introduced by infrastructure or software changes.
Testing Principles for Speed and Confidence
We have adopted several testing principles at Basis Theory which enable us to rapidly develop and refactor our product, provide faster feedback loops, and identify business requirements. These principles have been tested across several organizations of various sizes in various industries.
Bias towards Acceptance Tests over Unit Tests
Unit tests have value for edge cases such as checking (de)serialization of data, encrypt/decrypt operations, or checking for breaking schema changes in an API. Still, due to their limited scope, they rarely help assert an application's business functionality. We have found that focusing on acceptance tests enables our team to refactor our systems without changing our tests rapidly and enables us to validate external dependencies such as reading and writing to a database.
Acceptance testing focuses more on how the system should behave than how the system is implemented. Leveraging Behavior-Driven Development (BDD) frameworks such as Cucumber can also unlock the ability for less-technical individuals to help write acceptance tests that the engineering team can implement.
Test one thing at a time
We have found that writing lots of tests, which perform a small number of assertions, enables us to have more declarative tests, e.g., test names that describe the behavior being tested. An example of this would be:
- Should Register User - This test name is not declarative as there may be multiple assertions around a user record written to a database, an email sent to the user, and a background process started to generate a new profile automatically. This test does not describe the business requirement of the test.
- Should Send Welcome Email When User Registers - This declarative test verifies a single thing: that a new welcome email was sent when the user registered. It is simple to understand the business requirement that is being tested.
Add a dash of randomness
Randomness adds confidence to our tests by asserting the application's behavior satisfies the acceptance criteria. To do this, we leverage testing libraries to generate fake data models that satisfy the API, allowing us to verify the behavior of the system without limiting our test scenarios to a few known possibilities.
For example, say we need to test a calculator function that returns the sum of two numbers. If we only assert that calling the method with 2 and 2 returns 4, the implementation could be doing addition, multiplication, x^y, or hard-coded to return “4”. Randomly generating the inputs catches these bugs. By randomizing the values, they may be 3 and 6, which should return 9, eliminating the non-addition or hard-coded operations.
Treat the system as a black box
Black-box testing checks the inputs and outputs of the system, allowing engineers to change easily or even replace the application with a new solution without modifying the tests themselves. This gives engineers a way to test end-to-end paths through an application, making them useful for proving API endpoint security, input validation, business functionality, and external dependencies— such as a new record was written to the database or a call to an external system occurred—all work as intended.
Immutable Artifacts
Recompiling or changing our software system between deployment stages introduces potential regressions that need to be retested. In order to reduce this potential risk, we want to compile our software systems exactly once and promote the resulting artifact between deployment stages. (Examples of these artifacts include a Docker container or a compiled binary.)
To do this, we compile the software system and run Unit, Acceptance, and UI Tests to ensure business requirements are satisfied prior to merging the change and promoting it to a deployed environment. Changes to the application’s behavior should be accomplished via configuration changes and tested using Integration, Synthetic, Load, Security, and Compliance testing.
If it’s hard to test, it’s hard to integrate
Acceptance tests are the first integration with the public interface because they mimic actual customers and systems integration with the product. Complex acceptance tests indicate that the integration will be difficult for customers or that the underlying system will be difficult and costly to maintain.
Utilize deep-object equality assertions
Deep-object equality enables developers to test multiple assertions on an object or result simultaneously and fail the test if any assertions fail. Compared to traditional individual assertions, developers can verify all conditions in a single test execution in a single assertion versus running the test multiple times to pass each assertion. Many testing libraries offer this behavior, such as .NET’s FluentAssertions or JavaScript’s Chai.
Have questions or feedback? Join the conversation in our Slack community!




.jpeg)
